Build Your Own Retrieval Agent with Langchain x Langgraph
Building simple RAG application using Gemini, FAISS, and Langchain

In this guide, I will share with you how to build AI Agent leveraging Langchain and their powerful state management called Langgraph.
Agent
Some of you may already understand what agent and how they capable of. Agent is a system capable of decision making by leveraging LLMs. An system may has several of LLM to complete such of complex tasks
Objective
We are gonna build Retrieval Augmented Generation (RAG) Agent that can make decision when gonna use Vector Database (Query) and evaluate their answer.
Prerequisites
- Python 3.10 or above
- Google Gemini API. You can register here https://aistudio.google.com/apikey
Start Code
Install Libraries
1
pip install langchain langgraph langchain-community tiktoken langchain-google-genai langchainhub faiss-cpu langchain-text-splitters
Embedding
In this project, we will utilize the embedding model indobenchmark/indobert-base-p1 from HuggingFace. This model is specifically designed to support the Indonesian language, making it highly suitable for our use case. Embedding models transform text data into dense numerical representations (vectors) that capture the semantic meaning of the text. This is essential for tasks such as document retrieval, clustering, and similarity comparison.
1
2
3
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name='indobenchmark/indobert-base-p1')
For alternative embedding models, you can explore other options available on HuggingFace. A useful tip is to reference the MTEB (Massive Text Embedding Benchmark) Leaderboard, which ranks embedding models based on their performance across various tasks. Selecting a model ranked higher on the leaderboard can help achieve more accurate and robust results.
Vector Store
A vector store is a database designed to store documents in their vectorized (numerical) form. These numerical representations allow for efficient similarity searches and other vector-based operations. Examples of popular vector stores include Chroma DB, Pinecone, and QDrant, each with unique features and use cases.
In this implementation, we will use FAISS (Facebook AI Similarity Search), an open-source library developed by Facebook. FAISS is well-known for its efficiency and performance in large-scale vector similarity searches. It often provides results on par with or even better than other vector stores mentioned above, making it a reliable choice for our project. Additionally, FAISS is well-documented and widely supported, which simplifies integration and troubleshooting.
Document Processing
Processing documents is a critical step to ensure that they are appropriately prepared for embedding and subsequent operations. This stage involves loading the raw documents and segmenting them into manageable chunks that maintain context.
- Document Loader: For this project, we will use PyPDFLoader, a Python-based library for loading PDF documents. This tool extracts text data from PDF files and prepares it for further processing. It is particularly useful for handling unstructured or semi-structured documents.
- Chunking Method: To enhance processing, we will apply Recursive Character Chunking, a technique that breaks down documents into smaller text chunks while preserving meaningful context. This method ensures that the embedding model can process the text effectively without losing the semantic structure of the document. Proper chunking is crucial as it directly impacts the quality of the embeddings and the overall performance of the vector search system.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.docstore.in_memory import InMemoryDocstore
import faiss
def documents_processing(document, chunk_size: int, chunk_overlap: int, embedding_model: str, dimension: int) -> FAISS:
loader = PyPDFLoader(file_path=document)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
chunks = text_splitter.split_documents(docs)
embeddings = HuggingFaceEmbeddings(model_name=embedding_model)
vector_store = FAISS(
embedding_function=embeddings,
index=faiss.IndexFlatL2(dimension),
docstore=InMemoryDocstore(),
index_to_docstore_id={}
)
vector_store.add_documents(chunks)
return vector_store
RAG (Custom Tool)
To build our Retrieval-Augmented Generation (RAG) tool, we will leverage two powerful libraries: LangChain(specifically the BaseTool class) and Pydantic (a robust data validation library). These tools enable us to create a fully customizable retrieval system tailored to our needs. Below is a breakdown of the process:
Overview of the Custom Tool Design
The custom tool is implemented as a Python class, and it comprises two key components:
Input Class
This class is responsible for defining the input schema. It inherits from Pydantic’s
BaseModel, which provides a clean and robust way to validate data.- The
Input Classspecifies the variables required by the tool. - Variables are defined using Pydantic’s
Fieldfunction, allowing you to:- Add metadata such as descriptions, default values, titles, and constraints.
- Validate inputs seamlessly before processing.
- Example:
1 2 3 4 5 6
from pydantic import BaseModel, Field class InputSchema(BaseModel): query: str = Field(..., description="The search query", title="Query") max_results: int = Field(5, description="Maximum number of results to return", title="Max Results")
- The
Main Class
This class represents the actual tool and inherits from LangChain’s
BaseTool. It defines the tool’s name, description, and functionality. The main class contains the business logic that executes the tool’s operations.- The
Main Classis where the tool’s core functionality is implemented. - Key components to define:
- Tool Name: A short identifier for the tool.
- Tool Description: A detailed explanation of what the tool does, used by the Language Model (LLM) for decision-making.
- Response Format: Specify how outputs will be returned.
- Core Functionality:
- Implement the tool’s business logic inside the
_runmethod. This method executes the tool’s defined operations, such as performing searches or interacting with a retrieval system.
- Implement the tool’s business logic inside the
- Example:
1 2 3 4 5 6 7 8 9 10 11 12 13
from langchain.tools import BaseTool class CustomRetrievalTool(BaseTool): name: str = "retrieval_tool" description: str = "A tool to retrieve relevant documents based on a query." response_format: str = "content_and_artifact" # The function to handle the actual process def _run(self, query: str, max_results: int = 5) -> str: # Example business logic results = f"Retrieving {max_results} results for query: '{query}'" return results
- The
- Important Notes
- Variable Usability: The variables you define in the input schema are consumed by the Language Model (LLM). This enables the model to take informed actions based on the tool’s defined behavior and constraints.
- Execution: By defining business logic in the
_runmethod, the tool can be directly invoked for tasks such as document retrieval or validation. - Official Guide: For a detailed walkthrough, refer to the LangChain Custom Tool Documentation.
- Final Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from langchain_community.vectorstores import FAISS
from langchain_core.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
class RetrieverInput(BaseModel):
query: str = Field(description="Query User untuk mencari informasi pada dokumen")
class Retrieve(BaseTool):
name: str = "document_retrieve_tool"
description: str = "Gunakan tools ini untuk mencari informasi berkaitan dengan Akuntansi, Finansial, dan Perbankan"
response_format: str = "content_and_artifact"
args_schema: Type[BaseModel] = RetrieverInput
vector_store: FAISS
search_type: str
k: int
def _run(self, query: str) -> dict[str, any]:
retrieve_docs = self.vector_store.similarity_search(query=query, k=self.k)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\n" f"Content: {doc.page_content}")
for doc in retrieve_docs
)
return serialized, retrieve_docs
Define Graph
This is where LangGraph, a powerful state management library, comes into play. LangGraph helps structure the flow of actions in a systematic and manageable way. We will define a simple yet effective flow to guide the agent’s decision-making process. Here’s how it works:
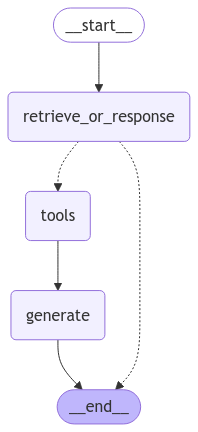
Agent’s Decision Flow
Initial Evaluation
The agent begins by evaluating the user’s query. It determines whether:
- A direct response can be generated based on existing knowledge or predefined rules.
- Document retrieval is necessary to provide a comprehensive or accurate response.
Custom Tool Integration
If the agent determines that document retrieval is needed, it will:
- Call the Custom Tool: This refers to the tool we defined earlier using
BaseToolandPydantic. The tool will handle document retrieval by interacting with the vector store and returning the most relevant documents based on the query.
- Call the Custom Tool: This refers to the tool we defined earlier using
Conclusion Generation
After retrieving the documents:
- The agent processes the retrieved information.
- It generates a detailed and context-aware response, incorporating the information from the documents to answer the user’s query effectively.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
from langgraph.graph import MessagesState, StateGraph, END
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.checkpoint.memory import MemorySaver
def graph_architecture(vector_store, search_type, k) -> StateGraph:
graph_builder = StateGraph(MessagesState)
tools = ToolNode([Retrieve(vector_store=vector_store, search_type=search_type, k=k)])
memory = MemorySaver()
graph_builder.add_node("retrieve_or_response", lambda MessagesState: retrieve_or_response(MessagesState, vector_store, search_type, k))
graph_builder.add_node(tools)
graph_builder.add_node("generate", generate)
graph_builder.set_entry_point("retrieve_or_response")
graph_builder.add_conditional_edges(
"retrieve_or_response",
tools_condition,
{
END: END,
"tools": "tools"
}
)
graph_builder.add_edge(start_key="tools", end_key="generate")
graph_builder.add_edge(start_key="generate", end_key=END)
graph = graph_builder.compile(checkpointer=memory)
graph_builder.add_edge(start_key="tools", end_key="generate")
graph_builder.add_edge(start_key="generate", end_key=END)
graph = graph_builder.compile(checkpointer=memory)
return graph
Testing the Agent
To ensure the defined flow of our Agent works as expected, we will test it using the pretty_print() function from LangGraph. This function visually displays the steps taken by the Agent, allowing us to verify its decision-making process and execution path.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
question= "apa itu SAK ETAP"
config = {
"configurable": {
"thread_id": str(uuid.uuid4())
}
}
inputs = {
"messages": [{
"role": "human",
"content": question,
}]
}
for step in graph.stream(input=inputs, config=config, stream_mode="values"):
step["messages"][-1].pretty_print()
Below is a sample output from the defined Agent during testing:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
================================[1m Human Message [0m=================================
apa itu SAK ETAP
==================================[1m Ai Message [0m==================================
Tool Calls:
document_retrieve_tool (7fa87e47-c0d1-41b5-811f-aed83acd03d5)
Call ID: 7fa87e47-c0d1-41b5-811f-aed83acd03d5
Args:
query: apa itu SAK ETAP
=================================[1m Tool Message [0m=================================
Name: document_retrieve_tool
Source: {'source': '../temp/document.pdf', 'page': 60}
Content: kreditur. SAK ETAP membantu perusahaan kecil menengah dalam
menyediakan pelaporan keuangan yang tetap relevan dan andal. SAK ETAP
akan khusus digunakan unutk perusahaan tanpa akuntabilitas publik yang
signifikan. Perusahaan yang terdaftar dalam bursa efek dan yang memiliki
akuntabilitas publik signifikan tetap harus menggunakan PSAK yang umum.
1.2 Pengakuan Unsur Laporan Keuangan
Menurut SAK ETAP nomor 2 paragraf 24, pengakuan unsur laporan keuangan
Source: {'source': '../temp/document.pdf', 'page': 61}
Content: kreditur. SAK ETAP membantu perusahaan kecil menengah dalam
menyediakan pelaporan keuangan yang tetap relevan dan andal. SAK ETAP
akan khusus digunakan unutk perusahaan tanpa akuntabilitas publik yang
signifikan. Perusahaan yang terdaftar dalam bursa efek dan yang memiliki
akuntabilitas publik signifikan tetap harus menggunakan PSAK yang umum.
1.2 Pengakuan Unsur Laporan Keuangan
Menurut SAK ETAP nomor 2 paragraf 24, pengakuan unsur laporan keuangan
Source: {'source': '../temp/document.pdf', 'page': 62}
Content: Laporan laba rugi memasukkan semua pos penghasilan dan beban yang diakui
dalam suatu periode kecuali SAK ETAP mensyaratkan lain. SAK ETAP
mengatur perlakuan berbeda terhadap dampak koreksi atas kesalahan dan
perubahan kebijakan akuntansi yang disajikan sebagai penyesuaian terhadap
periode yang lalu dan bukan sebagai bagian dari laba atau rugi dalam periode
terjadinya perubahan (Ikatan Akutan Indonesia, 2009a : 5.2). Laporan laba rugi
[HumanMessage(content='apa itu SAK ETAP', additional_kwargs={}, response_metadata={}, id='6dbebeae-81f2-476e-aeaa-f94e91051428'), AIMessage(content='', additional_kwargs={'function_call': {'name': 'document_retrieve_tool', 'arguments': '{"query": "apa itu SAK ETAP"}'}}, response_metadata={'prompt_feedback': {'block_reason': 0, 'safety_ratings': []}, 'finish_reason': 'STOP', 'safety_ratings': [{'category': 'HARM_CATEGORY_HATE_SPEECH', 'probability': 'NEGLIGIBLE', 'blocked': False}, {'category': 'HARM_CATEGORY_DANGEROUS_CONTENT', 'probability': 'NEGLIGIBLE', 'blocked': False}, {'category': 'HARM_CATEGORY_HARASSMENT', 'probability': 'NEGLIGIBLE', 'blocked': False}, {'category': 'HARM_CATEGORY_SEXUALLY_EXPLICIT', 'probability': 'NEGLIGIBLE', 'blocked': False}]}, id='run-4c56f492-6b32-4938-9cf2-1bab4eed1e1d-0', tool_calls=[{'name': 'document_retrieve_tool', 'args': {'query': 'apa itu SAK ETAP'}, 'id': '7fa87e47-c0d1-41b5-811f-aed83acd03d5', 'type': 'tool_call'}], usage_metadata={'input_tokens': 66, 'output_tokens': 11, 'total_tokens': 77, 'input_token_details': {'cache_read': 0}}), ToolMessage(content="Source: {'source': '../temp/document.pdf', 'page': 60}\nContent: kreditur. SAK ETAP membantu perusahaan kecil menengah dalam \nmenyediakan pelaporan keuangan yang tetap relevan dan andal. SAK ETAP \nakan khusus digunakan unutk perusahaan tanpa akuntabilitas publik yang \nsignifikan. Perusahaan yang terdaftar dalam bursa efek dan yang memiliki \nakuntabilitas publik signifikan tetap harus menggunakan PSAK yang umum. \n \n1.2 Pengakuan Unsur Laporan Keuangan \n Menurut SAK ETAP nomor 2 paragraf 24, pengakuan unsur laporan keuangan\n\nSource: {'source': '../temp/document.pdf', 'page': 61}\nContent: kreditur. SAK ETAP membantu perusahaan kecil menengah dalam \nmenyediakan pelaporan keuangan yang tetap relevan dan andal. SAK ETAP \nakan khusus digunakan unutk perusahaan tanpa akuntabilitas publik yang \nsignifikan. Perusahaan yang terdaftar dalam bursa efek dan yang memiliki \nakuntabilitas publik signifikan tetap harus menggunakan PSAK yang umum. \n \n1.2 Pengakuan Unsur Laporan Keuangan \n Menurut SAK ETAP nomor 2 paragraf 24, pengakuan unsur laporan keuangan\n\nSource: {'source': '../temp/document.pdf', 'page': 62}\nContent: Laporan laba rugi memasukkan semua pos penghasilan dan beban yang diakui \ndalam suatu periode kecuali SAK ETAP mensyaratkan lain. SAK ETAP \nmengatur perlakuan berbeda terhadap dampak koreksi atas kesalahan dan \nperubahan kebijakan akuntansi yang disajikan sebagai penyesuaian terhadap \nperiode yang lalu dan bukan sebagai bagian dari laba atau rugi dalam periode \nterjadinya perubahan (Ikatan Akutan Indonesia, 2009a : 5.2). Laporan laba rugi", name='document_retrieve_tool', id='ed2cf23e-a610-4c2c-87cb-4f3d2b1a7d48', tool_call_id='7fa87e47-c0d1-41b5-811f-aed83acd03d5', artifact=[Document(metadata={'source': '../temp/document.pdf', 'page': 60}, page_content='kreditur. SAK ETAP membantu perusahaan kecil menengah dalam \nmenyediakan pelaporan keuangan yang tetap relevan dan andal. SAK ETAP \nakan khusus digunakan unutk perusahaan tanpa akuntabilitas publik yang \nsignifikan. Perusahaan yang terdaftar dalam bursa efek dan yang memiliki \nakuntabilitas publik signifikan tetap harus menggunakan PSAK yang umum. \n \n1.2 Pengakuan Unsur Laporan Keuangan \n Menurut SAK ETAP nomor 2 paragraf 24, pengakuan unsur laporan keuangan'), Document(metadata={'source': '../temp/document.pdf', 'page': 61}, page_content='kreditur. SAK ETAP membantu perusahaan kecil menengah dalam \nmenyediakan pelaporan keuangan yang tetap relevan dan andal. SAK ETAP \nakan khusus digunakan unutk perusahaan tanpa akuntabilitas publik yang \nsignifikan. Perusahaan yang terdaftar dalam bursa efek dan yang memiliki \nakuntabilitas publik signifikan tetap harus menggunakan PSAK yang umum. \n \n1.2 Pengakuan Unsur Laporan Keuangan \n Menurut SAK ETAP nomor 2 paragraf 24, pengakuan unsur laporan keuangan'), Document(metadata={'source': '../temp/document.pdf', 'page': 62}, page_content='Laporan laba rugi memasukkan semua pos penghasilan dan beban yang diakui \ndalam suatu periode kecuali SAK ETAP mensyaratkan lain. SAK ETAP \nmengatur perlakuan berbeda terhadap dampak koreksi atas kesalahan dan \nperubahan kebijakan akuntansi yang disajikan sebagai penyesuaian terhadap \nperiode yang lalu dan bukan sebagai bagian dari laba atau rugi dalam periode \nterjadinya perubahan (Ikatan Akutan Indonesia, 2009a : 5.2). Laporan laba rugi')])]
[SystemMessage(content="Kamu merupakan asisten AI bernama DesiAI yang ahli dalam bidang Akuntansi,Finansial dan Perbankan. Gunakanlah Tools Retrieve untuk mencari informasi berdasarkan dari query yang diberikan. Kombinasikan pengetahuanmu dengan informasi yang diberikan agar menghasilkan jawaban yang akurat.\n\nSource: {'source': '../temp/document.pdf', 'page': 60}\nContent: kreditur. SAK ETAP membantu perusahaan kecil menengah dalam \nmenyediakan pelaporan keuangan yang tetap relevan dan andal. SAK ETAP \nakan khusus digunakan unutk perusahaan tanpa akuntabilitas publik yang \nsignifikan. Perusahaan yang terdaftar dalam bursa efek dan yang memiliki \nakuntabilitas publik signifikan tetap harus menggunakan PSAK yang umum. \n \n1.2 Pengakuan Unsur Laporan Keuangan \n Menurut SAK ETAP nomor 2 paragraf 24, pengakuan unsur laporan keuangan\n\nSource: {'source': '../temp/document.pdf', 'page': 61}\nContent: kreditur. SAK ETAP membantu perusahaan kecil menengah dalam \nmenyediakan pelaporan keuangan yang tetap relevan dan andal. SAK ETAP \nakan khusus digunakan unutk perusahaan tanpa akuntabilitas publik yang \nsignifikan. Perusahaan yang terdaftar dalam bursa efek dan yang memiliki \nakuntabilitas publik signifikan tetap harus menggunakan PSAK yang umum. \n \n1.2 Pengakuan Unsur Laporan Keuangan \n Menurut SAK ETAP nomor 2 paragraf 24, pengakuan unsur laporan keuangan\n\nSource: {'source': '../temp/document.pdf', 'page': 62}\nContent: Laporan laba rugi memasukkan semua pos penghasilan dan beban yang diakui \ndalam suatu periode kecuali SAK ETAP mensyaratkan lain. SAK ETAP \nmengatur perlakuan berbeda terhadap dampak koreksi atas kesalahan dan \nperubahan kebijakan akuntansi yang disajikan sebagai penyesuaian terhadap \nperiode yang lalu dan bukan sebagai bagian dari laba atau rugi dalam periode \nterjadinya perubahan (Ikatan Akutan Indonesia, 2009a : 5.2). Laporan laba rugi\n\n", additional_kwargs={}, response_metadata={}), HumanMessage(content='apa itu SAK ETAP', additional_kwargs={}, response_metadata={}, id='6dbebeae-81f2-476e-aeaa-f94e91051428')]
==================================[1m Ai Message [0m==================================
SAK ETAP (Standar Akuntansi Keuangan Entitas Tanpa Akuntabilitas Publik) adalah standar akuntansi yang ditujukan untuk perusahaan kecil dan menengah yang tidak memiliki akuntabilitas publik signifikan. SAK ETAP membantu perusahaan-perusahaan ini dalam menyajikan laporan keuangan yang relevan dan andal. Perusahaan yang terdaftar di bursa efek atau memiliki akuntabilitas publik yang signifikan tetap harus menggunakan PSAK (Pernyataan Standar Akuntansi Keuangan) umum.
Result
All systems are functioning as expected! The Agent takes the right path and handles queries effectively
Conclusion
We have outlined the process of building a Retrieval-Augmented Generation (RAG) system, integrating key components like custom tools, state management with LangGraph, and testing workflows. By leveraging LangChain’s BaseTool and Pydantic for tool customization, we ensured robust input validation and dynamic functionality. LangGraph further streamlined the decision flow, enabling the Agent to evaluate queries, retrieve relevant documents, and generate context-aware responses efficiently.
Testing confirmed that the Agent followed the defined path accurately, demonstrating its ability to handle queries effectively. This system ensures a reliable, scalable, and intelligent document retrieval and response generation process.